Paper Review: Efficient Virtual Memory for Big Memory Servers
- 5 minsPaper Review: Efficient Virtual Memory for Big Memory Servers
Citation
Basu, A., Gandhi, J., Chang, J., Hill, M. D., & Swift, M. M. (2013, June). Efficient virtual memory for big memory servers. In ACM SIGARCH Computer Architecture News (Vol. 41, No. 3, pp. 237-248). ACM.
Images in this article are taken from the paper - all credits to the authors.
Summary
An Oversimplified Abstract
Virtual Memory + Paging cause systems that have a lot of memory (think 96GB+ of RAM per server) and particular workloads to be slow because they spend a lot of time dealing with TLB misses. Allowing a contiguous section of virtual memory to map to a contiguous section of physical RAM allows us to avoid many TLB misses and the penalties from them, making those workloads faster.
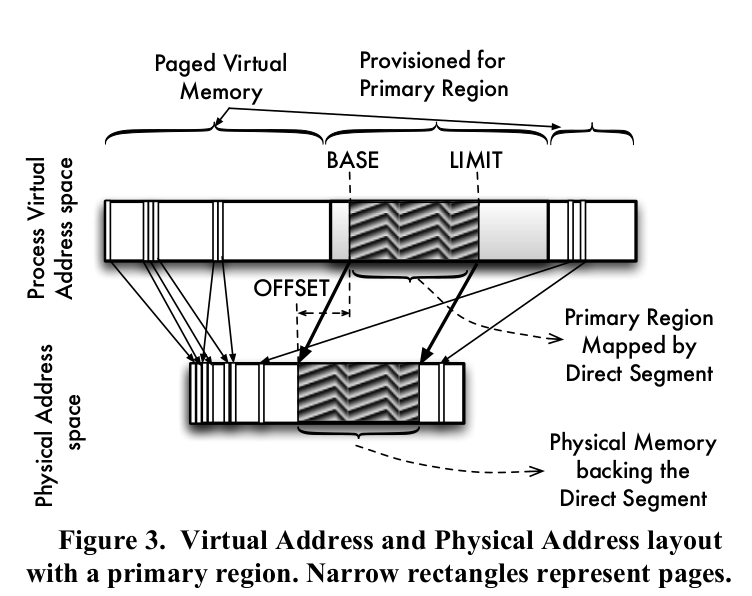
(Image taken from the research paper)
Fundamental Premises:
- There are “big-memory” server workloads, imagine a single server with 96GB of RAM
- If we use small pages (say 4KB), on graph workloads, with a virtual memory + paging system (even without swapping), we could get up to 51% of our execution cycles serving TLB misses alone!
- In general: many workloads spend much more time handling TLB misses on these larger memory systems
- Increasing the page size is insufficient to solve the problem (but it helps!)
- These big-memory workloads do not need swapping, fragmentation mitigation, fine-grained page-wise protection. They take a performance hit due to TLB misses. They also have processes that run for a long time, match the capacity of memory provisioned, and only have a few processes running anyways.
- Large applications also use pointer-based lookup data structures to handle their large data sets. This also reduces locality and hurts the TLB and caches.
Paper’s contribution:
- We can add direct segment hardware that allows us to map some contiguous virtual memory to this contiguous block of physical memory (the direct segment).
- This mapping is dynamic: applications can choose how much of their virtual memory space is mapped to this contiguous physical memory
(Image taken from the research paper)
Results from experiments
- For all workloads examined (graph500, memcached, MySQL, NPB:BT, NPB:CG, GUPS) - the percentage of time spent on TLB miss handling was reduced to less than 0.5%.
Conclusions
Adding direct segments for large-memory workloads (think data centers, etc) will likely improve performance by decreasing time spent on TLB miss handling.
In-depth
Key Concepts
- Paging, Segmentation, Virtual Memory, TLBs
- Large Pages (HugePages)
Large Pages
The time spent servicing TLB misses reduces as the size of pages in the system increases. This is because each TLB now has more reach, which is governed by 2 factors: the size of the pages and number of TLB entries. The TLB reach is how much of the memory space is accessible through the TLB alone (total size of the memory mapped by the TLB). Experimental results from the paper show the percentage of cycles used to service D-TLB misses reducing from 51.1% to 9.9% to 1.5% for the graph500 benchmark as the page size increases from 4KB to 2MB to 1GB.
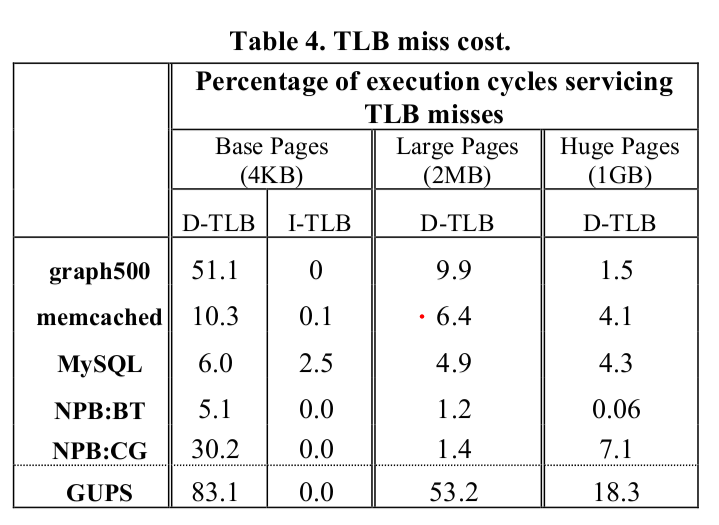
(Image taken from the research paper)
So why not just keep increasing the page size?
There are multiple reasons why this isn’t the best idea, and the paper mentions many of them. Firstly, the page size idea isn’t scalable. While there are multiple options available (4KB, 2MB, 1GB); they’re very different from each other, and need changes to the hardware configuration (different TLB hierarchies, number of entries, etc) to scale. The granularity of the page size selection is pretty much up to OS and hardware designers, and the existing page sizes may not fit our current workload (imagine if RAM size was 32 GB, and all we had was maybe 1GB and 512GB pages).
So constantly increasing / changing the page size for the current system isn’t a good long-term solution to the problem of high TLB miss penalties for big-memory workloads.
Hardware needed and usage
- 3 registers: BASE, LIMIT and OFFSET
- Base register: start address of the contiguous virtual memory mapped directly
- Limit register: end address of the contiguous virtual memory mapped directly
- Offset register: start of the contiguous physical memory area that backs this mapping
If a virtual address V is within base and limit, disable TLB translation, physical address is V + offset.
If not, do normal paging.
The OS will load these registers correctly for each program that requests this contiguous memory segment.
Changes made to Linux
Linux 2.6.32 was modified to reserved virtual and physical memory for the direct-mapping implementation. The direct-mapping was achieved by modifying the page fault handler and doing the translation in software.
Related work
- Large Page support (e.g. HugeTLBfs)
- Research to make TLBs more efficient
Questions
- For long-running workloads, could we slowly optimize the virtual - physical mapping by placing important things in the direct segment?
- Could we collect the best-performance mappings over time in the OS to optimize future runs of the program?
- Am still not sure what portion of the virtual memory space was direct-mapped during the evaluation runs. Doesn’t make sense that everything was mapped, since there still are TLB misses.
- Answer: seems like the applications that ran used a syscall to reserve the “primary region” that is direct-mapped. All heap allocations + anonymous mmaps are put inside unless mmap has a flag to indicate otherwise.
- Is this realistic? We’re essentially changing all heap allocations to be directly mapped to contiguous RAM. Will we have this contiguous RAM? (yes if we reserve it on bootup) But so many things could go wrong: if you have multiple processes using the direct-mapped segment, you could have all kinds of fragmentation. It just feels like removing paging for almost all dynamic memory allocation - clearly this will reduce TLB miss rates and therefore the overall penalty.