Paper Review: The Load Slice Core Microarchitecture
Paper Review: Load-Slice Core Microarchitecture
Citation
Carlson, T. E., Heirman, W., Allam, O., Kaxiras, S., & Eeckhout, L. (2015, June). The load slice core microarchitecture. In Computer Architecture (ISCA), 2015 ACM/IEEE 42nd Annual International Symposium on (pp. 272-284). IEEE.
Images in this article are taken from the paper - all credits to the authors.
Summary
An Oversimplified Abstract
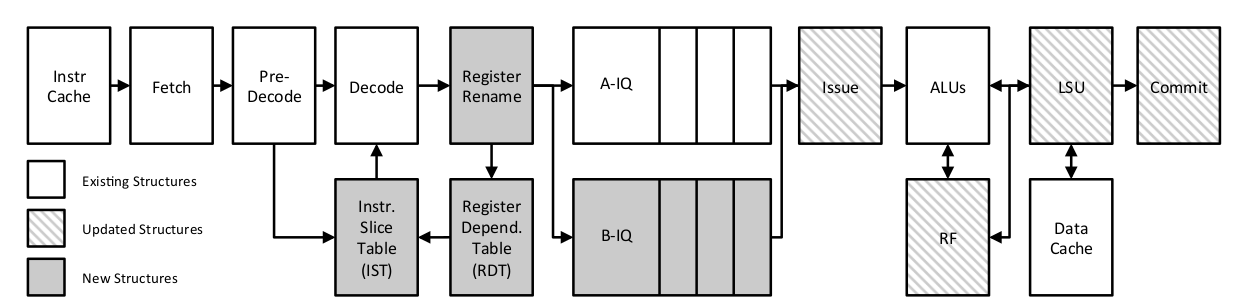
Adding a second pipeline (B-IQ in image below) (that handles memory-related instructions) to an in-order processor makes this new architecture faster than a naive in-order processor (of course), but also makes it more power and size efficient over a traditional out-of-order processor.
(Image taken from the research paper)
Fundamental Premises:
- Current architectures are out-of-order, superscalar, heavy focus on ILP extraction
- Useful side effects besides ILP extraction: parallel cache and memory operations are possible
- Parallel memory operations (Memory Hierarchy Parallelism [MHP]) are now more important because of memory wall
- However, these these architectures are complex and power-hungry
- For multicore processors in power + energy constrained environments, energy efficiency is replacing single-thread performance as the main concern
Paper’s contribution:
Suggests a new processor architecture to:
- extract MHP (memory hierarchy parallelism)
- while maximizing energy efficiency
- through extending a in-order + stall-on-use pipeline with
- a second in-order pipeline that bypasses stalled instructions in the first pipeline
- this pipeline focuses on memory access and address generating instructions
- this works using a novel iterative algorithm that extracts these instructions through 2 extra hardware components
This is called the Load-Slice Core.
(Image taken from the research paper)
Results from experiments
- Increased performance over in-order processor by 53%. Downside: 15% area increase, 22% power increase. Overall increase in energy-efficiency (MIPS/Watt) by 43%.
- Increase in energy efficiency (MIPS/Watt) over out-of-order processors by >4.7x or >470%.
- [My note] Note that actual performance as compared to out-of-order will definitely be lower, since ILP is not fully extracted here.
- If power and area is restricted (what parameters?): 53% performance improvement over in-order, 95% over out-of-order.
Conclusions
This is a possible direction for future processors to take.
In-depth
Key Concepts
- Memory wall: widening gap between CPU and memory access latencies. Main memory is much slower than the CPU.
- Superscalar computers
- Speculation
- Out-of-order processors
- Address-Generating Instructions
- Scoreboarding
- Tomasulo’s Algorithm
- Register renaming
Hardware needed
- IST: Instruction Slice table (a cache): contains addresses of instructions belonging to a backwards slice (instruction we intend to put into the bypass queue)
- RDT: Register Dependency Table: which instruction (pointer) last wrote to this register? (contains mappings for all registers)
- Register Renaming hardware: supports the speculative execution of instructions in the bypass queue
Iterative Backwards Dependency Analysis
Method discussed in the paper of iteratively discovering which instructions (a sequence of instructions usually) are generating addresses for load/store instructions. We want to issue those instructions to the bypass queue so that they can execute independently of a long load/store on the main queue.
If a section of code is executed multiple times: we iteratively optimize it in hardware, with the end goal of allowing slices of code that end in a load/store to execute in the bypass queue while the main queue is blocked.
- When we have a load/store:
mul (r9 + rax*8), xmm1the first time this instruction is run (it will be in the bypass queue), we notice that an instruction before it is producing the address for it:add rdx, raxfor e.g. So this prev. instruction will provide part of the address formul (r9 + rax*8), xmm1- specificallyrax. We insert the add instruction into the IST - The 2nd time this section of code is run: we put
add rdx, raxandmul (r9 + rax*8), xmm1into the bypass queue. Say one more instruction above it affectsrax:mul r8, rax- so we also note that in the IST. - The 3rd time this section of code is run,
mul r8, rax,add rdx, rax, andmul (r9 + rax*8), xmm1go into the bypass queue so that we can run this in parallel with some long independent load/store that we assume to be happening in this example.
Store instruction handling
If a load instruction overlaps with earlier store instruction: possible memory dependency.
Resolution: a store instruction is split into 2 parts: (1) address calculation part (2) collect data and update memory part. (1) is put into the bypass queue, (2) is in the main queue. This makes stores with an unresolved address automatically block future loads (the bypass queue is in-order)
Experimental Setup
- Sniper multi-core simulator
- Cycle-level simulation of in-order and out-of-order core models as baselines
- They extended the simulator to add the Load-Slice core microarchitectures
- All cores are 2-wide superscalar, same execution units, same cache, have hardware prefetchers (fetch code/data(?) into some cache before execution)
- They increase the branch misprediction penalties for L-S core and O-o-O architectures since the pipeline is longer (rename, dispatch)
- 28nm
- SPEC CPU2006 benchmark, SimPoint methodology
- NAS Parallel Benchmarks
- SPEC OMP2001 suites
- Area and power estimates from CACTI
Results
In terms of IPC, in-order < Load-Slice < OoO
Load-Slice outperforms both in area-normalized performance (MIPS/mm^2) and energy efficiency (MIPS/W)
They also compared the three if we had a power budget of 45W and max area of 350 mm^2 - if we could fit as many cores as possible, which set of cores is best? Many Load-Slice seems to outperform in-order and OoO clusters.
Related work
- Run-ahead execution to discover + prefetch independent memory accesses
- Slice processors - extract independent program slices that can be run separately from current blocked instruction flow (these slices may not be contiguous!)
- Software only techniques that use SMT hardware contexts to execute important slices early
- Helper threads
- Speculative pre-computation
- DAE
- braid microarchitecture
- speculative slice execution
- OUTRIDER
- flea-flicker multi-pass pipelining
Further reading needed
To define:
- stall-on-use [contextually from paper: when the memory reference is used for something and it’s currently being written to - it will stall on the second instruction that is trying to access it]. This contrasts to a stall-on-miss processor where the moment we have a long-latency load (miss?) - we stall the pipeline.
- CAM (vs RAM, FIFO)
- Backwards slices
- front-end of pipeline vs back-end of processor?